Akár offtopic, akár nem, gondoltam mesélek kicsit arról, hogy mire jutottam az elmúlt két napban a korábban már bemutatott EFPIA-közzétételek adatainak feldolgozása kapcsán. Az ötletet az egyik kommentelő adta, aki rámutatott arra, hogy mekkora vita zajlik Angliában is éppen most erről (náluk is most kellett ezeket az adatokat közzétenni); kiindulópontnak ezt és ezt az írást javaslom.
Van azonban a dolognak még egy vetülete: Angliában az Oxfordi Egyetem Ben Goldacre és Anna Powell-Smith vezette EBM Data Lab-ja (amúgy iszonyú jó dolgaik vannak ettől függetlenül is, mindenkinek csak ajánlani tudom) elindított egy projektet, melynek célja, hogy gépi úton feldolgozzák és kiértékeljék a nyilvánosságra hozott adatokat... hogy értelmet is adjanak ennek a rengeteg számnak.
Én ugyan nem vagyok komplett kutatócsoport, így a lehetőségeim is korlátozottabbak, de az ötlettől nagyon fellelkesültem, így megnéztem, hogy mit lehet kezdeni a magyar adatokkal.
- A költéseknek sok cégnél meghatározó (néhánynál kishíján kizárólagos) része a kutatás és fejlesztés (K+F), melyet nem kell nevesíteni, egyetlen aggregált soron szerepel.
- Ez ráadásul nem döntés kérdése, szemben a szakembereknek és szervezeteknek adott juttatásokkal: maga a transzparencia kódex deklarálja, hogy így kell közzétenni; elgondolkodtató, hogy akik megírták a kódexet, azok nyilván tisztában voltak az 1.-es pontban szereplő ténnyel, magyarán annak tudatában dolgozták ki az egész procedúrát, hogy egyes cégeknél a költés néhány százalékának transzparenciájáról szól az egész történet...
- A nevesített juttatások egyetlen általam látott gyógyszercégnél sincsenek összesítve. A nem nevesítettek vannak (persze, hiszen azok csak úgy vannak megadva), tehát megtudjuk, hogy hányan és hány forintot kaptak, de a nevesítettek csak egyesével szerepelnek. Azaz, ha valaki össze akarja például vetni, hogy hányan és mennyit kaptak aszerint, hogy nevesítettek voltak-e vagy sem, akkor előbb össze kell adnia a nevesítetteket, ami kézzel nyilván ezer évig tartana...
- ... viszont géppel sem olyan könnyű. Néhány gyógyszergyár ugyanis gondoskodott róla (nem akarok rosszindulatú lenni, simán lehet, hogy egyszerűen nem is gondoltak erre, és nem direkt csinálták), hogy ne legyen egyszerű dolga annak, aki ezt akarja. Volt, aki épeszű módon feldolgozható formátumban rakta ki (Excel, HTML, vagy legalább olyan PDF amiben nincs letiltva a hozzáférés a szöveghez), de többen minimum védett PDF-be rakták, sőt, egy-két vicces játékos képként (!) tette közzé, hogy még OCR-programmal se nagyon lehessen értelmesen használatba venni a benne lévő információt... Én azok körében, amiket eddig megnéztem, a következőket tapasztaltam:
Feldolgozható formátum Nem feldolgozható, de legalább szöveges Nem is szöveges Amgen Bayer AstraZeneca Biogen Novo Nordisk Pfizer Chiesi Sanofi Takeda GSK Servier
A lista semmiképp nem teljes, és semmiféle logika nincsen benne, egyszerűen ezek jöttek szembe először tegnap éjjel, mielőtt elnyomott volna az álom... Az első oszlopból a Biogen kivételével megcsináltam mindegyiket (annál valamiért nagyon elcsúsztak a sorok, nem volt erőm kidolgozni), a másodikból a Novo Nordisk-et megcsináltam, a többinél már nem volt erőm az OCR-ezéshez (meg kibogozni a lehetőségeket, miután az első erre a célra talált weboldalon elfogyott az ingyenes kvótám :) ), a harmadiknál a Pfizer-t megpróbáltam be-OCR-ezni, de elég reménytelen lett... - Annál a sornál, hogy hány személy/szervezet kapta a nem nevesített támogatásokat, néhány cég megadta az értéket az összesen-nél is, néhány nem. A dolog azért nem mindegy, mert ezt nem lehet kitalálni a részletszámokból: abból, hogy valaki 2 személynek fizetett regisztrációs díjat és 3-nak utazást, még nem következik, hogy 5 személynek fizetett bármit is (ad abszurdum az is lehet, hogy egyetlen egy kapta az összeset). A transzparencia kódex sajnos nem fogalmaz egyértelműen, mert azt írja, hogy "a 3.1 szakaszban ismertetett kategóriák valamelyikéhez ésszerűen hozzá lehet rendelni", de az ebből nem derül ki, hogy a kategóriák összesen rovata kategóriának tekintendő-e... tehát lehet, hogy azok sem jártak el szabálytalanul, akik nem adták meg ezt az adatot (pedig ezzel információ veszett el). Éppen ezért amikor majd az egy főre jutó támogatást számolom, ott nem fogok tudni összesen-t megadni, kénytelen voltam kategóriánként külön-külön.
Ezek fenntartásával a fent említett 5 cég adatait összeraktam, és írtam hozzá egy R-szkriptet ami elvégzi az elemzést. Hogy magam is transzparens legyek, természetesen közzéteszek nyilvánosan minden adatot, ami az itteni elemzések reprodukálásához szükséges:
- A nyers, cégek által közzétett adatok: Nyers.zip (az összes amit letöltöttem, nem csak az, amit feldolgoztam).
- Az 5 feldolgozott cég adatai: a nevesített közzétételek feldolgozva (Feldolgozott.zip) és az aggregált adatok feldolgozva (Aggregalt.xlsx).
- És végül a talán legfontosabb: a feldolgozást végző R-szkript (EFPIA_process_1.R). Remek példa a melt/cast szemléltetésére, annyit kellett pofoznom az adatokat... A vizualizáció – természetesen – lattice-szal készült; ennek előnyeiről már korábban is áradoztam a blogon.
Lássuk most az eredményeket!
Előtte pár fontos figyelmeztetés:
- No warranty whatsoever. Éjjel 1-kor egyáltalán nem biztos, hogy jó helyre raktam minden számot... (De nagy örömmel veszem ha valaki leellenőriz.)
- Még egyszer: az adatok NEM teljeskörűek, nagyjából hasraütésszerű minta azokból, amiket egyáltalán fel tudtam dolgozni. Sajnos elég sok cikkel el vagyok maradva, meg bírálnom is kell, úgyhogy nem valószínű, hogy rövidtávon lenne időm szisztematikusan végigmenni az összes közzétételen, de ha valaki úgy érzi, hogy ennek az egésznek van értelme, és szívesen besegítene, akkor örömmel veszem (email-címem szokásosan jobb oldalt).
- Nagyon fontos, hogy a nevesítésről NEM a gyógyszercégek döntöttek, hanem a támogatottak. Ezt azért mondom, mert óva intenék mindenkit attól, hogy ez alapján nekiálljon kitalálni, hogy ki a legtranszparensebb gyógyszergyár, meg a legaljasabb, meg hasonlók: ők csak adminisztrálták a döntést, de azt magát a támogatottak hozták meg. Ebből tehát nem lehet arra következtetni, hogy melyik gyógyszergyár mennyire transzparens (legfeljebb arra, hogy a támogatottjai mennyire azok).
- Két dolgot szeretnék hangsúlyozni az adatok értelmezése kapcsán. Az egyik, hogy bár talán nekem kell a legkevésbé magyaráznom, hogy a transzparencia elszánt híve vagyok, de azért azt is látni kell, hogy ennek vannak határai. A gyógyszercégek versenypiacon élnek (mégpedig a mi döntésünkből, lévén, hogy piacgazdaságban és nem tervgazdaságban vagyunk), így a transzparencia nem lehet korlátlan, hiszen egy ponton túl már a gazdasági hatékonyságot rontaná, márpedig a gyógyszergyárak hatékony működése szintén fontos társadalmi érdek. Nem kérdés persze, hogy annak nyilvánosnak kell lennie, hogy mely orvosok és mennyiből utaztak gyógyszergyári pénzen, és elképesztő, hogy ide csak most jutottunk el, de nyilván nem lehet transzparens mondjuk a teljes stratégiájuk. A lényeg, hogy a kettő között van szürke zóna; ez leginkább a fent emlegetett K+F költségeknél lehet jó kérdés... A másik, hogy minden diszfunkcionalitásával együtt – amit nekem megint csak nyilván nem kell magyarázni, lévén, hogy épp most igyekszem felhívni rá a figyelmet – azt is látni kell, hogy a gyógyszeripar így is a talán legjobban szabályzott, és könnyen lehet, hogy történetesen a legtranszparensebb iparágak egyike. Avagy meg tudja nekem mondani bárki, hogy mennyit költött és hogyan és kinek és mikor reklámozásra a vállalat, ami a csokoládét állította elő, amit elmajszolt miközben ezt a blogbejegyzést olvasta, vagy a cég, ami az autóját gyártotta, amivel utazni fog miután végzett az olvasással?! Persze, világos, hogy a gyógyszerek sokkal közvetlenebb befolyást gyakorolnak életünkre, és ez indokolja a különbséget (természetesen, épp ezért támogatom én is a transzparenciát), de már abban sem vagyok tökéletesen biztos, hogy ez a különbségtétel arányos azzal, amennyi hatást gyakorolnak ránk a gyógyszerek egyfelől és az autók vagy az édességek másfelől...
És akkor most már tényleg lássuk, hogy mi jött ki mindebből!
Elsőként a kifizetett összegeket néztem meg különféle bontásokban. Később nyilván elsősorban a nevesített és nem nevesített kifizetések összevétésére leszünk kíváncsiak, úgyhogy előkészítő lépésként nézzük őket meg külön-külön is.
Kezdjük a nevesített juttatásokkal. Cégek szerint megbontva így néz ki:
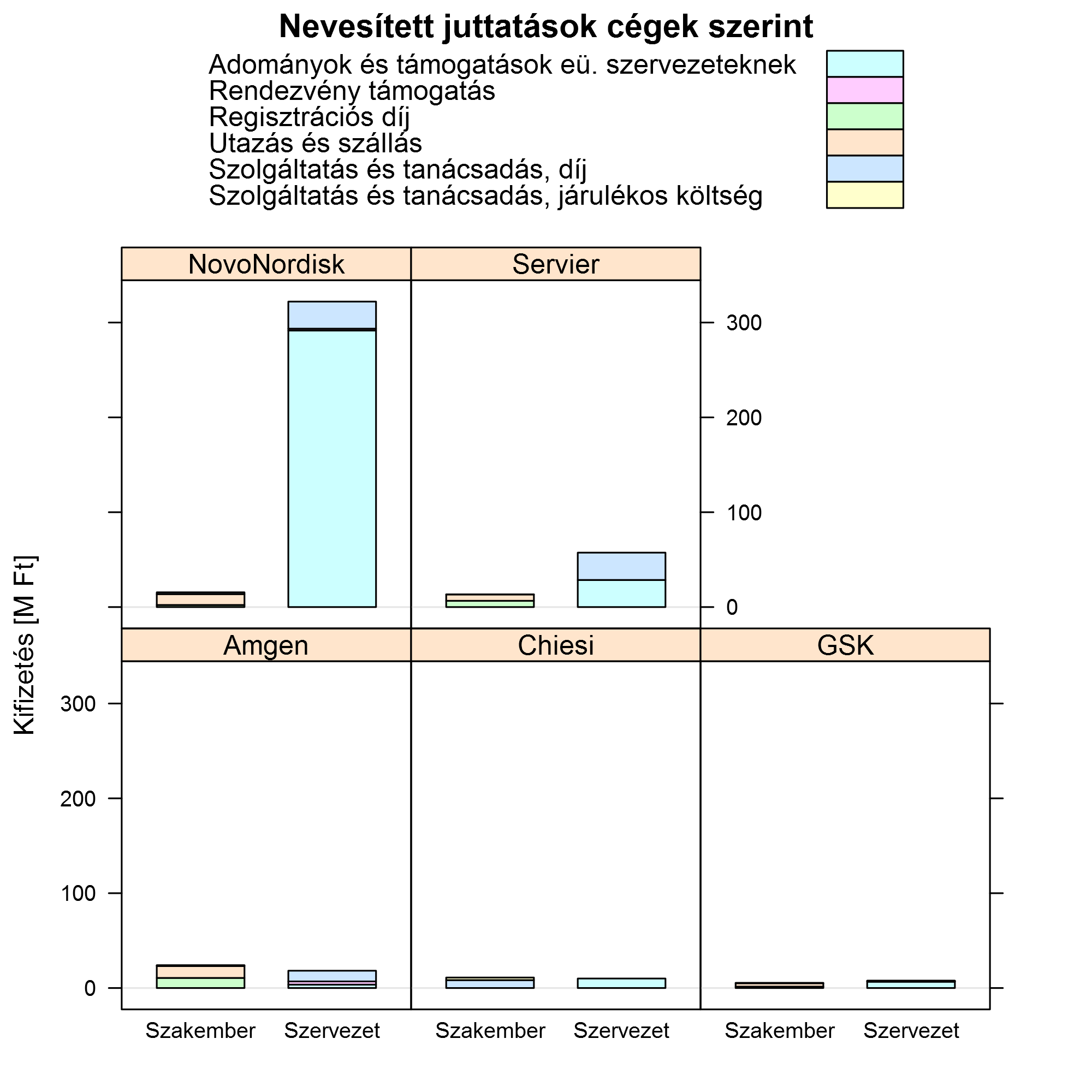
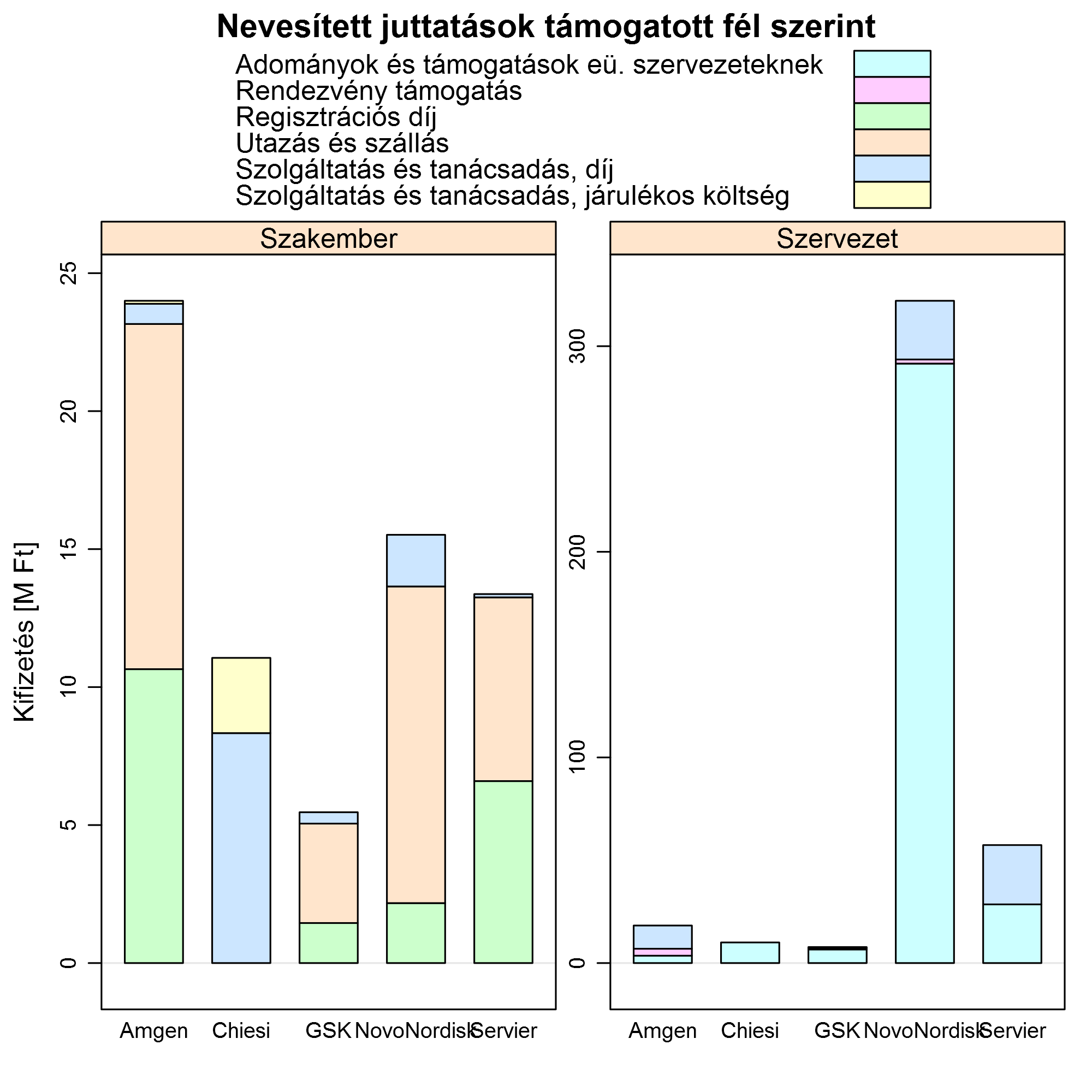
Ha támogatott szerint csoportosítunk, akkor érdemes nem egyféle skálázáson ábrázolni a paneleket, hiszen a szakemberek és a szervezetek nagyon eltérnek egymástól (míg a cégeknél mondhatjuk, hogy azokat össze akarjuk egymással is vetni):
Most lássuk a nem nevesített kifizetéseket; ugyanilyen módon. Cég szerint csoportosítva:
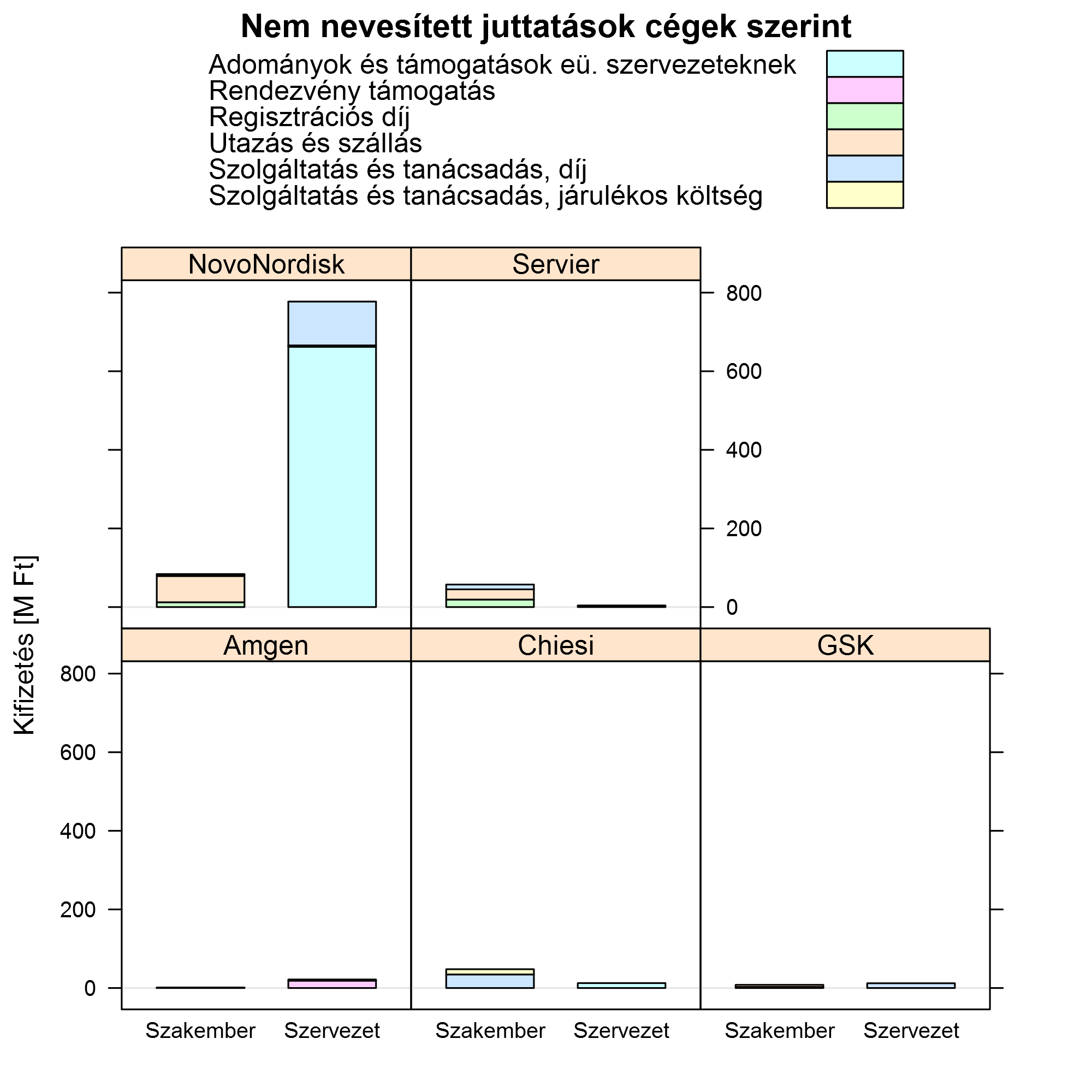
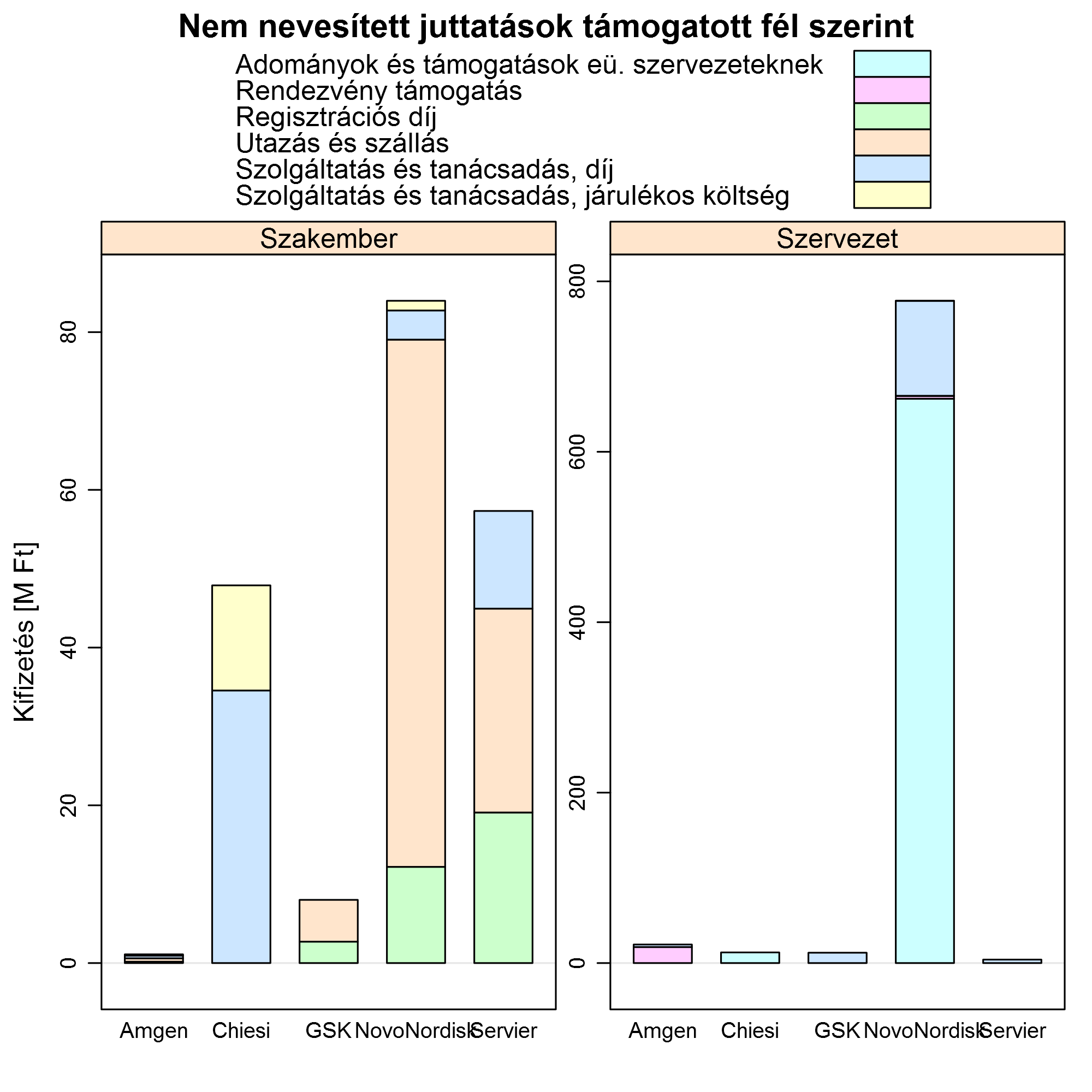
Támogatott szerint csoportosítva:
Ezek után rátérhetünk a talán legérdekesebb kérdésre: a kettő összevetésére. A nagyságrendek belövése végett ezen már feltüntettem a K+F összegeket is:
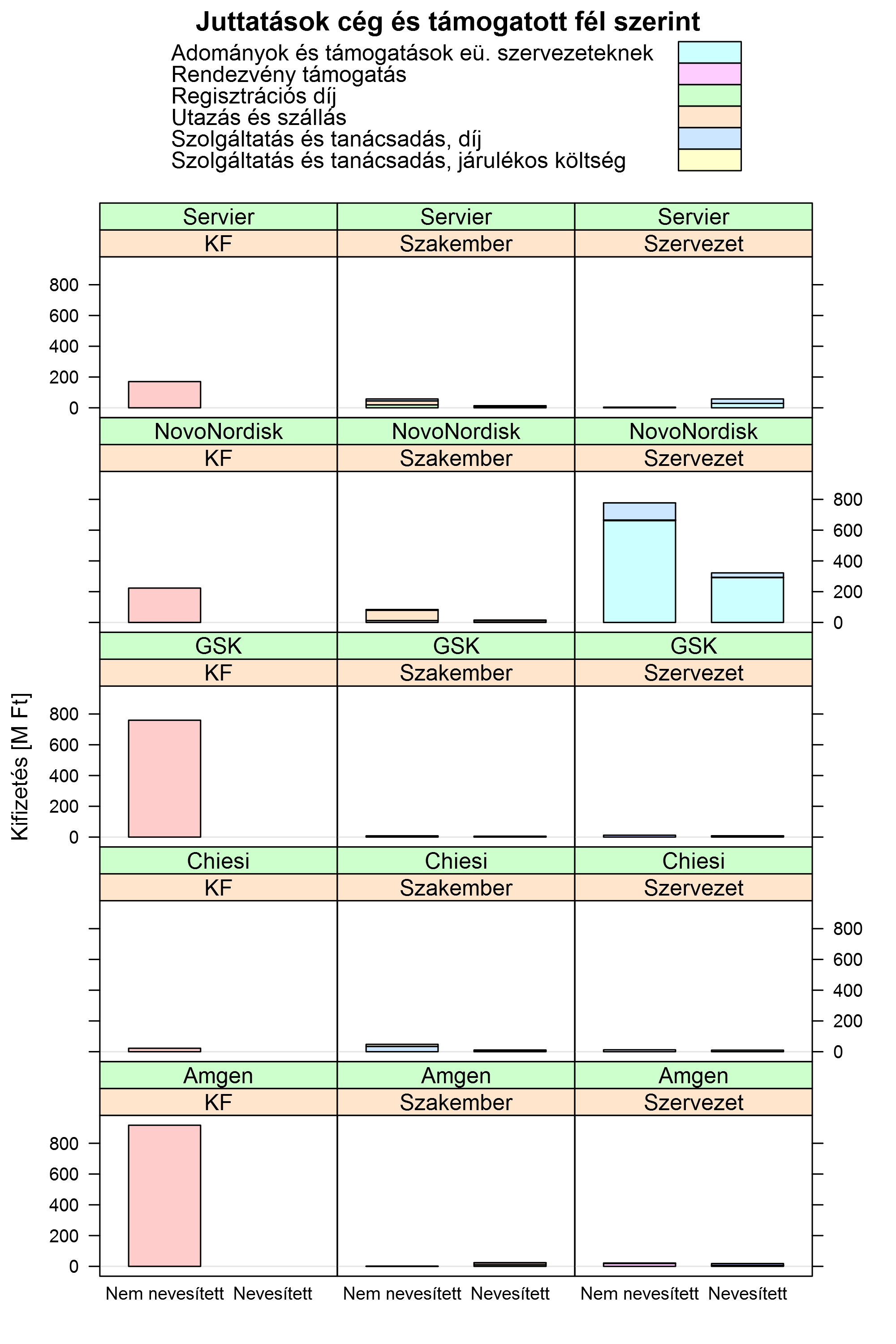
Ez az ábra már egyértelműen átvezet minket a közvetlenül vizsgálandó kérdésre: a költések nevesítettség szerinti elemzésére. E célból nézzük meg az összegeket, immár a kategóriával nem törődve:
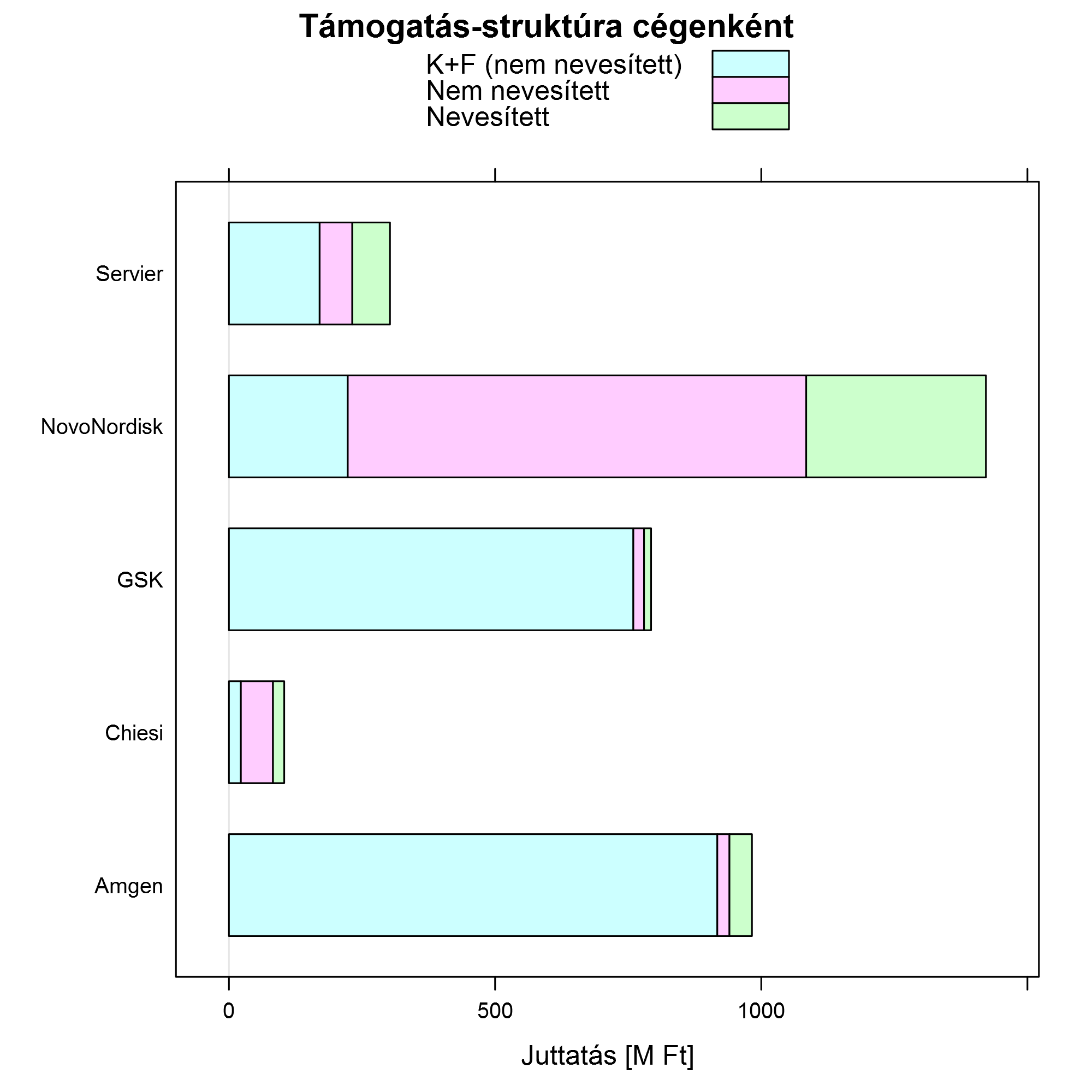
Tanulságos, ha áttérünk a cégen belüli arányokra:
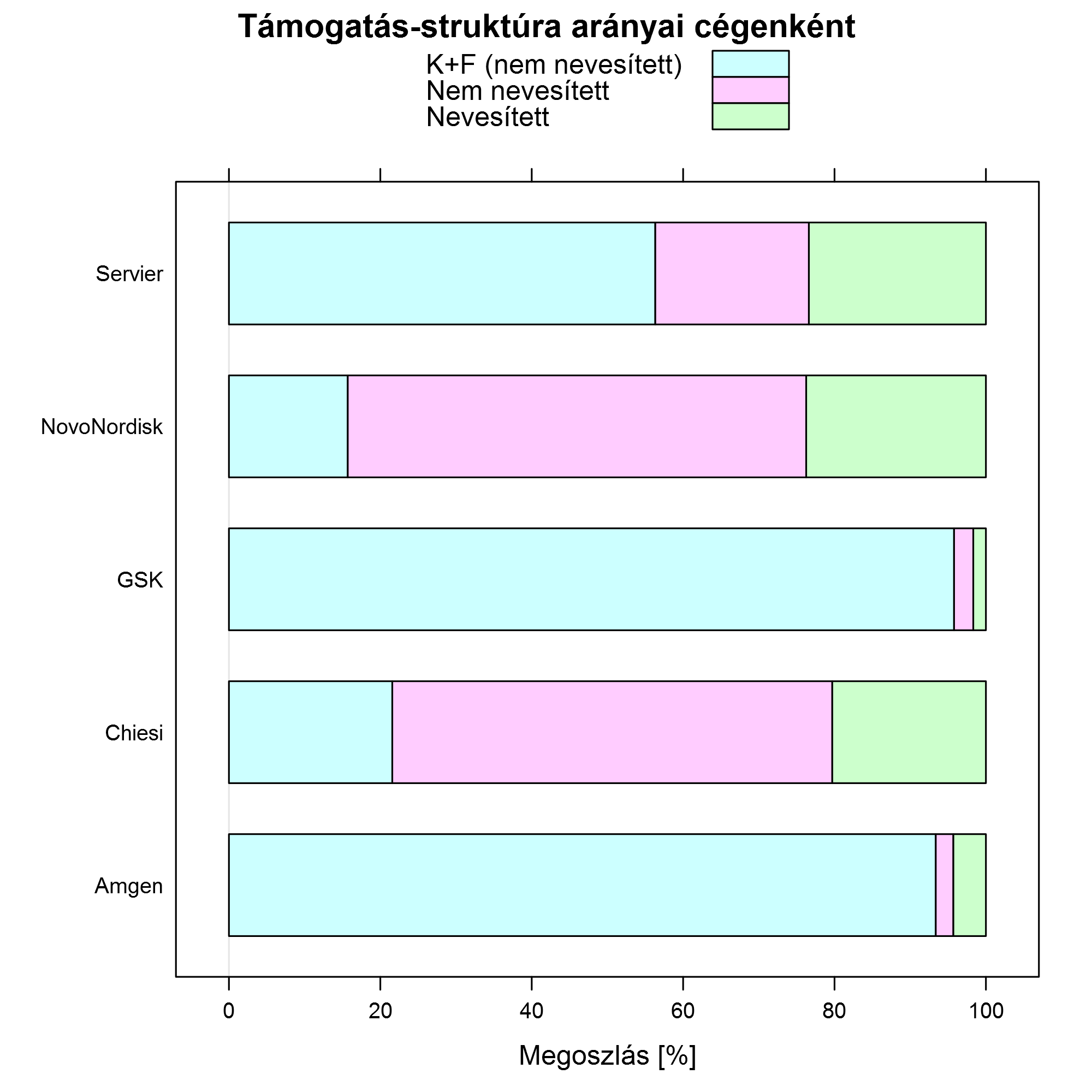
Látható, hogy nincs cég, ahol a nevesített arány a 24%-ot meghaladná (de van, ahol a 2%-ot (!) sem éri el!).
Ha most a K+F-től eltekintünk, mondván, hogy csak az egyáltalán "elvileg nevesíthető" részt nézzük, akkor a következőt látjuk:
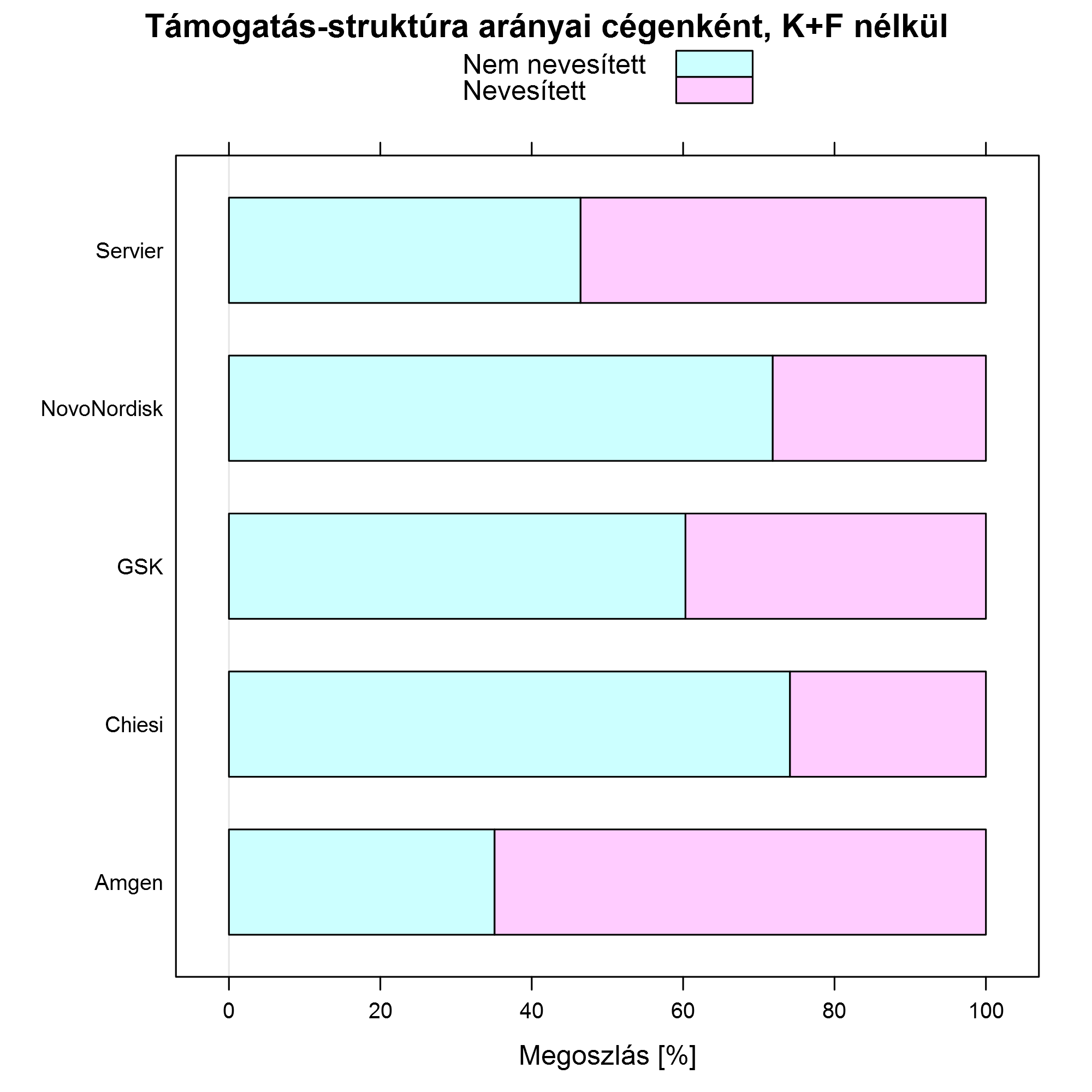
És végezetül nagyon érdekes kérdés az is, hogy a támogatásokra magukra mi jellemző. Amit meg tudunk mondani, hogy hányan kaptak:
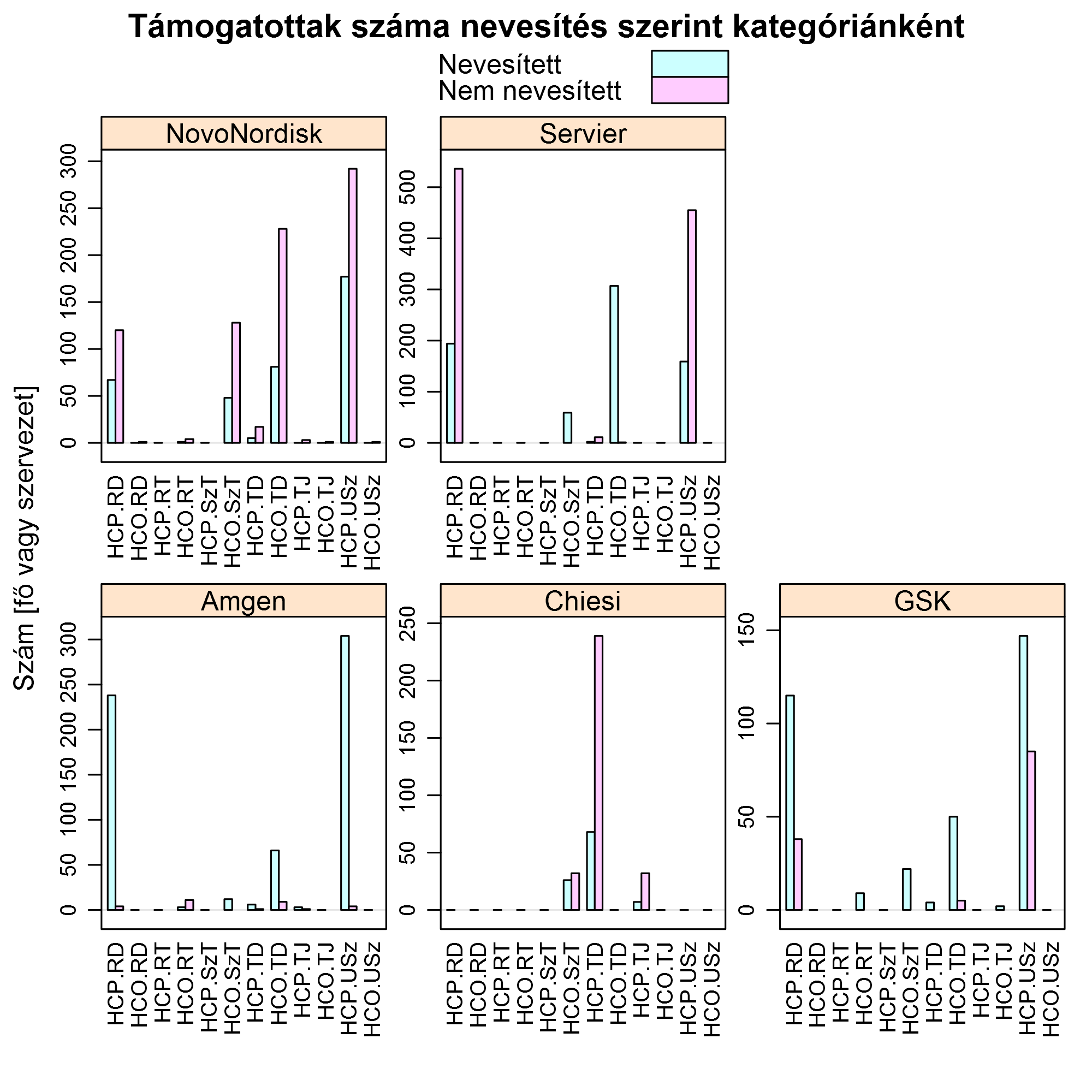
És hogy milyen értékben:
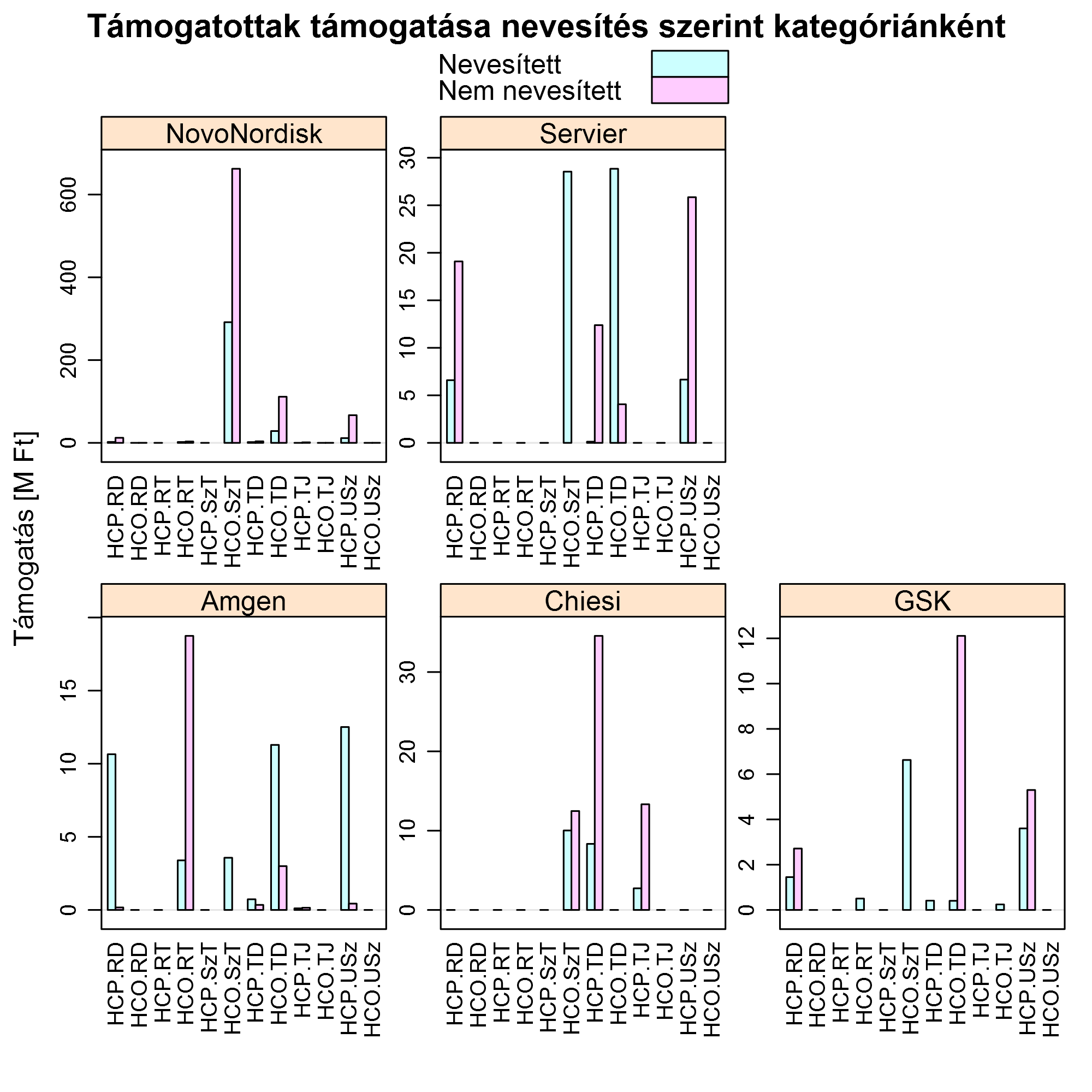
(Itt rövidítettem a kategóriák neveit, hogy több látszódjon az ábrán. HCP: szakember, HCO: szervezet; RD: Regisztrációs díj, RT: Rendezvény támogatás, SzT: Adományok és támogatások eü. szervezeteknek, TD: Szolgáltatás és tanácsadás, díj, TJ: Szolgáltatás és tanácsadás, járulékos költség, USz: Utazás és szállás.)
Ami még érdekes, hogy milyenek a támogatottak által kapott támogatások összegei. A nevesített kategóriában ezt persze pontosan meg tudjuk mondani, épp ettől nevesített, akár teljes eloszlást is lehetne rajzolni, de ezt mivel vetjük össze? A nem nevesítetteknél csak két dolgot tudunk: az össz-támogatást, és hogy hányan kapták. Így tehát az egyetlen dolog, amit ki tudunk számolni, az átlag. Úgyhogy számoljuk ki ezt nevesítetteknél és nem nevesítetteknél is, hogy össze tudjuk őket vetni:
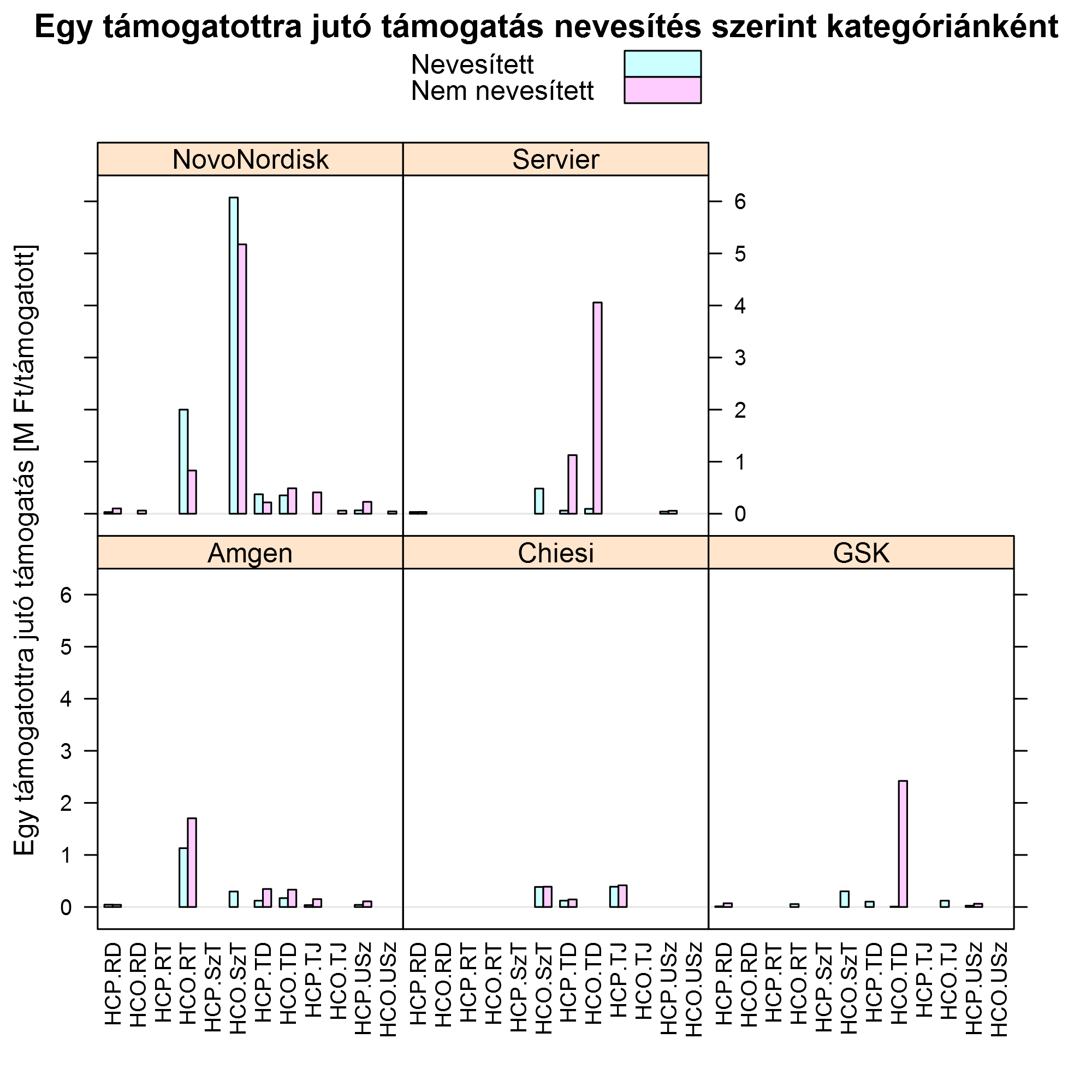 Nos, idáig jutottam! Természetesen nem csak az adatokra, hanem ezen elemzésekre is vonatkozik, hogy nem teljeskörűek. Egyszerűen ennyi jutott kapásból az eszembe, természetesen ehhez is örömmel veszek minden további ötletet, ha úgy tűnik, hogy van értelme ennek.
Nos, idáig jutottam! Természetesen nem csak az adatokra, hanem ezen elemzésekre is vonatkozik, hogy nem teljeskörűek. Egyszerűen ennyi jutott kapásból az eszembe, természetesen ehhez is örömmel veszek minden további ötletet, ha úgy tűnik, hogy van értelme ennek.
